I. Introduction
1.1 Motivation
Knowledge graph กลายเป็นสิ่งจำเป็นสำหรับการแสดงข้อมูลที่มีโครงสร้างในด้านการเงิน การแพทย์ และ e-commerce Knowledge graph ประกอบด้วย entity (node ที่แทนวัตถุในโลกจริง), relationship (edge ที่เชื่อมต่อ entity) และ ontology (schema ที่กำหนด type ที่ถูกต้อง)
Ontology กำหนดว่าอะไรสามารถถูก represent ได้ หาก concept มีอยู่ในโลกจริงแต่ไม่มีใน ontology จะไม่สามารถถูกบันทึกใน knowledge graph ได้ สิ่งนี้สร้างข้อจำกัดพื้นฐาน: เมื่อ domain เปลี่ยนแปลงและข้อมูลใหม่เข้ามา ontology จะกลายเป็นล้าสมัย
1.2 ตัวอย่างที่เป็นรูปธรรม
พิจารณา financial knowledge graph ที่มี ontology ง่ายๆ นี้:
- Entity type: COMPANY, COUNTRY, REGION
- Relationship: MEMBER_OF (Country → Region)
เมื่อประมวลผลเอกสารที่ระบุว่า:
"Saudi Arabia is a founding member of OPEC since 1960"
ระบบพบปัญหา:
- "OPEC" ไม่ใช่ COMPANY, COUNTRY หรือ REGION — มันเป็น international organization
- Membership relationship ระหว่าง Country และ Organization ไม่มีอยู่
หากไม่มี schema evolution ข้อมูลนี้จะสูญหาย Ontology evolution problem คือ: เราจะระบุ gap เหล่านี้และปรับปรุง schema อย่างเป็นระบบได้อย่างไรโดยรักษาคุณภาพข้อมูล?
1.3 แนวทางที่มีอยู่
แนวทางปัจจุบันมีข้อจำกัดที่สำคัญ:
Manual Evolution: Domain expert ตรวจสอบข้อมูลและปรับปรุง ontology ด้วยมือ สิ่งนี้รับประกันคุณภาพแต่ไม่ scale — expert ไม่สามารถตรวจสอบทุกเอกสาร และการปรับปรุง schema กลายเป็นคอขวด
Fully Automated Evolution: ระบบ machine learning ปรับเปลี่ยน ontology โดยไม่มีการกำกับดูแลจากมนุษย์ สิ่งนี้ scale ได้ดีแต่เสี่ยงต่อการสร้าง type ที่ซ้ำซ้อน ความไม่สอดคล้องทาง semantic และข้อผิดพลาดที่แพร่กระจายโดยไม่ถูกตรวจพบ
1.4 แนวทางของเรา
เราเสนอทางสายกลาง: AI-assisted evolution with human-in-the-loop approval ข้อมูลเชิงลึกที่สำคัญคือการแยก proposal generation (ซึ่ง AI สามารถทำได้ในขนาดใหญ่) ออกจาก decision-making (ซึ่งต้องการวิจารณญาณของมนุษย์)
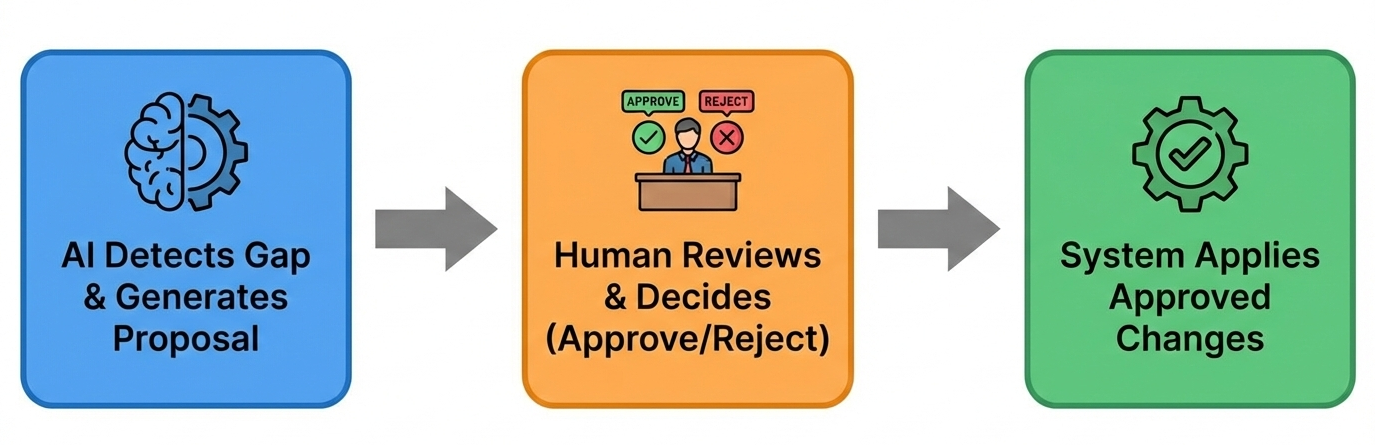
สิ่งนี้รวมความสามารถของ AI ในการประมวลผลเอกสารในขนาดใหญ่กับความเชี่ยวชาญของมนุษย์สำหรับการควบคุมคุณภาพ สมมุติฐานนั้นง่าย:
1.5 ความท้าทายทางเทคนิค
การ implement แนวทางนี้ต้องแก้ปัญหาหลายอย่าง:
ความท้าทายที่ 1: Context Limit Large language model มี context window ที่จำกัด Production ontology ที่มีหลายร้อย type เกินขีดจำกัดเหล่านี้ เราจัดการสิ่งนี้ผ่าน domain-based schema slicing — แบ่ง ontology ออกเป็น semantic domain และให้เฉพาะส่วนที่เกี่ยวข้องกับ LLM
ความท้าทายที่ 2: Gap vs. Error เมื่อการ extract ล้มเหลว อาจบ่งชี้ถึง schema gap ที่แท้จริง, data error หรือเพียงแค่เลือก domain ผิด ระบบต้องจำแนก failure ได้อย่างแม่นยำเพื่อหลีกเลี่ยงการสร้าง proposal ที่ไม่ถูกต้อง
ความท้าทายที่ 3: Proposal Conflict เอกสารต่างกันอาจทริกเกอร์ proposal ที่คล้ายกัน หากไม่มีการตรวจสอบ ระบบอาจเสนอ "PARTNERS_WITH" และ "COOPERATES_WITH" สำหรับ concept เดียวกัน เราใช้ embedding-based similarity detection เพื่อระบุ duplicate
ความท้าทายที่ 4: Review Backlog มนุษย์ไม่ได้พร้อมเสมอ Proposal สะสมระหว่าง review session ต้องการ batch processing ในขณะที่รักษาความสอดคล้อง
1.6 Contribution
บทความนี้มีส่วนร่วมสี่ประการ:
- Framework Design — สถาปัตยกรรมที่สมบูรณ์สำหรับ AI-assisted ontology evolution พร้อม human oversight
- Domain-Based Slicing — วิธีการจัดการ LLM context ผ่านการแบ่ง ontology
- Proposal Workflow — กระบวนการที่มีโครงสร้างตั้งแต่การตรวจจับ gap จนถึง human review และการ apply เป็น batch
- Embedding Validation — การตรวจจับ duplicate ด้วย similarity-based สำหรับคุณภาพ proposal
1.7 ขอบเขต
งานนี้นำเสนอ conceptual framework พร้อมคำแนะนำการ implement เราทราบว่า:
- นี่คือ framework design ไม่ใช่ production system
- การตรวจสอบเชิงทดลองวางแผนไว้สำหรับงานในอนาคต
- Human review ยังคงจำเป็น — นี่ไม่ใช่ระบบอัตโนมัติเต็มรูปแบบ
เป้าหมายคือการสร้างรากฐานสำหรับ AI-assisted knowledge graph maintenance
1.8 โครงสร้างบทความ
Section II ให้ background เกี่ยวกับ knowledge graph และงานที่เกี่ยวข้อง Section III นำเสนอ system architecture Section IV และ V อธิบายรายละเอียดการตรวจจับ gap และ human workflow Section VI พูดถึงการ implement Section VII และ VIII ครอบคลุมข้อจำกัดและบทสรุป