III. System Architecture
Section นี้นำเสนอ system architecture โดยรวม แนะนำแนวทาง two-layer LLM และ domain-based schema slicing
3.1 Architecture Overview
ระบบประกอบด้วย component หลักห้าส่วนที่ทำงานร่วมกันเพื่อประมวลผลเอกสาร ตรวจจับ gap สร้าง proposal และ apply การเปลี่ยนแปลงที่ได้รับอนุมัติ:
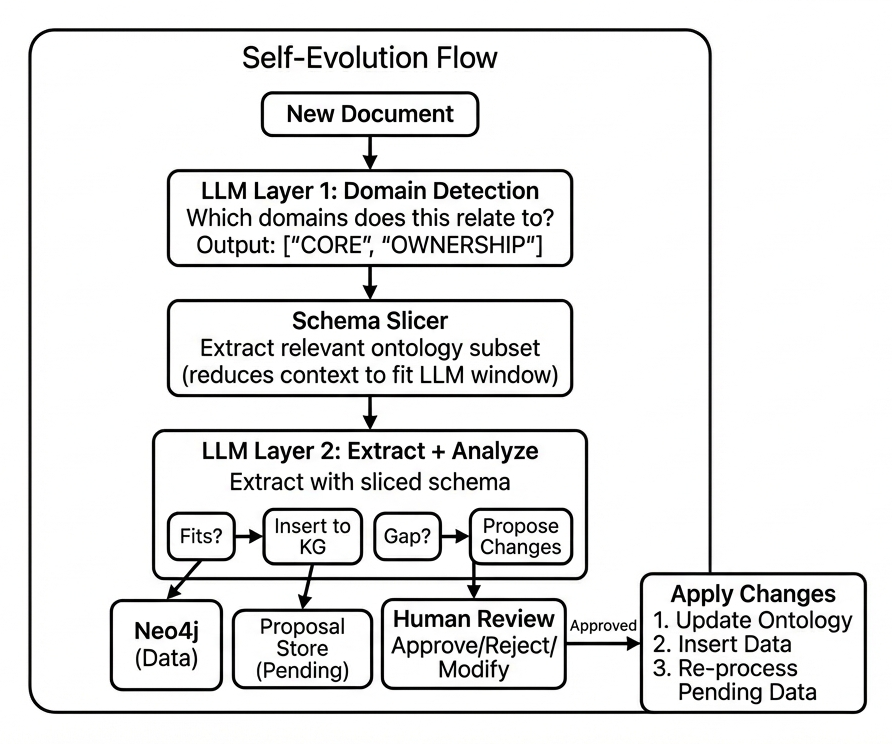
ความรับผิดชอบของ Component
- LLM Layer 1 — Domain detection: กำหนดว่า ontology domain ใดที่เกี่ยวข้องกับเอกสาร
- Schema Slicer — Extract เฉพาะส่วนที่เกี่ยวข้องของ ontology
- LLM Layer 2 — Extraction และ gap detection: พยายาม extract ข้อมูล ระบุ schema gap
- Proposal Store — เก็บ pending proposal สำหรับให้มนุษย์ตรวจสอบ
- Human Review — Approve, reject หรือแก้ไข proposal
3.2 Two-Layer LLM Architecture
แนวทางแบบไร้เดียงสาจะให้ ontology ทั้งหมดกับ LLM ตัวเดียว สิ่งนี้ล้มเหลวในทางปฏิบัติเพราะ production ontology มักเกิน context limit วิธีแก้ของเราแบ่งงานออกเป็นสอง layer เฉพาะทาง
ทำไมต้องสอง Layer?
พิจารณา production ontology ที่มี 50 entity type, 100 relationship type และ 200 pending proposal เมื่อ serialize อาจใช้ 35,000+ token — เกินขีดจำกัดของหลาย model และมีค่าใช้จ่ายสูง
แนวทาง two-layer ลดความต้องการ context อย่างมาก:
Layer 1: Domain Selection
Input: Document + Domain list (~500 tokens)
Output: Selected domains (1-3)
Total: ~3,000 tokens
Layer 2: Extract + Analyze
Input: Document + Sliced schema (~2,000)
+ Relevant proposals (~3,000)
Output: Triples + Gaps + Proposals
Total: ~7,000 tokens
รวม: ~10,000 token เทียบกับ ~35,000 สำหรับแนวทาง single-layer
Layer 1: Domain Detection
Layer แรกได้รับ domain listing แบบ lightweight และกำหนดความเกี่ยวข้อง โครงสร้าง prompt:
Available Domains:
SUPPLY_CHAIN
Use when: suppliers, vendors, sourcing
Covers: supply chain, manufacturing
OWNERSHIP
Use when: shareholders, investors
Covers: ownership stakes, holdings
PARTNERSHIP
Use when: joint ventures, alliances
Covers: business partnerships
---
Document: [document text]
Select 1-3 domains. Output JSON:
{"domains": [...], "reasoning": "..."}
Layer 2: Extraction and Analysis
Layer ที่สองได้รับเฉพาะ sliced schema บวก pending proposal สำหรับ domain เหล่านั้น มันพยายาม extract และรายงาน gap:
Schema (CORE + OWNERSHIP domains):
Entities:
COMPANY - Public or private company
COUNTRY - Nation
SHAREHOLDER - Entity holding shares
Relationships:
HEADQUARTERS_IN: Company -> Country
OWNS_SHARES: Shareholder -> Company
Pending Proposals:
PROP-042: Add ORGANIZATION entity
---
Document: [document text]
Extract triples using this schema.
Report any concepts that don't fit.
3.3 Domain-Based Schema Organization
Ontology ถูกแบ่งออกเป็น domain ทาง semantic — กลุ่มของ entity และ relationship type ที่เกี่ยวข้องกัน
โครงสร้าง Domain
แต่ละ domain ประกอบด้วย:
- ชื่อและคำอธิบาย
- Usage hint (เมื่อไหร่ควรเลือก domain นี้)
- Entity type ที่เกี่ยวข้อง
- Relationship type ที่เกี่ยวข้อง
- Flag (เช่น
always_include)
ตัวอย่าง domain สำหรับ financial knowledge graph:
CORE (always included)
Entities: COMPANY, COUNTRY, REGION
Rels: HEADQUARTERS_IN, MEMBER_OF
OWNERSHIP
Entities: SHAREHOLDER, FUND
Rels: OWNS_SHARES, MANAGES
SUPPLY_CHAIN
Entities: FACILITY, PRODUCT
Rels: SOURCES_FROM, MANUFACTURES_AT
PARTNERSHIP
Entities: JOINT_VENTURE
Rels: PARTNERS_WITH, FORMS_JV
Core Domain
CORE domain ประกอบด้วย type พื้นฐาน (COMPANY, COUNTRY) ที่เกี่ยวข้องกับ query ส่วนใหญ่ มันถูกรวมโดยอัตโนมัติในทุก slice เพื่อให้แน่ใจว่า entity type พื้นฐานพร้อมใช้งานเสมอ
Slicing Algorithm
เมื่อได้รับ domain ที่เลือก slicer จะดึง:
- Entity type ทั้งหมดที่อยู่ใน domain ที่เลือก + CORE
- Relationship type ทั้งหมดที่อยู่ใน domain ที่เลือก + CORE
- Pending proposal ที่ tag ด้วย domain เหล่านี้
อย่างเป็นทางการ เมื่อกำหนดชุดของ domain ที่เลือก $D_{sel}$ schema slice คือ:
$$S_{slice} = S_{CORE} \cup \bigcup_{d \in D_{sel}} S_d$$
โดยที่ $S_d$ หมายถึง schema element ทั้งหมด (entity, relationship) ที่อยู่ใน domain $d$ อัตราส่วนการลด context คือ:
$$r = 1 - \frac{|S_{slice}|}{|S_{full}|}$$
ในทางปฏิบัติ $r$ มักอยู่ระหว่าง 0.6 ถึง 0.8 หมายถึงการลด context 60-80%
3.4 Proposal Structure
เมื่อ LLM Layer 2 ตรวจพบ gap มันจะสร้าง structured proposal Proposal ประกอบด้วย:
{
"id": "PROP-042",
"title": "Add ORGANIZATION entity",
"status": "pending",
"domains": ["CORE"],
"ontology_changes": [
{
"type": "add_entity",
"name": "ORGANIZATION",
"description": "International org",
"properties": ["name", "org_type"]
},
{
"type": "add_relationship",
"name": "IS_MEMBER_OF",
"from": "COUNTRY",
"to": "ORGANIZATION"
}
],
"data_enrichment": {
"description": "OPEC + 13 members",
"sample_triples": [...]
},
"source": {
"document": "OPEC Report 2024",
"confidence": 0.92
}
}
ส่วนประกอบของ Proposal
- Ontology changes — การแก้ไข schema (add entity, add relationship, etc.)
- Data enrichment — Instance data ที่จะ insert เมื่อได้รับอนุมัติ
- Source — Provenance เชื่อมโยงไปยังเอกสารต้นทาง
3.5 Storage Architecture
ระบบใช้ storage แยกสำหรับ data type ที่แตกต่างกัน:
Neo4j (Graph Database)
- Entity instance
- Relationship instance
- Meta-schema (domain definition)
- ข้อมูลที่ APPROVED เท่านั้น
Postgres (Relational)
- Proposal record
- Status tracking
- Discussion history
- Pending extraction
pgvector (Vector Extension)
- Ontology embedding
- Proposal embedding
- สำหรับ similarity search
เหตุผลในการแยก
การแยก proposal ออกจาก production data ทำให้:
- Production graph มีเฉพาะข้อมูลที่ approved และ validate แล้ว
- Pending proposal ไม่ปนเปื้อน query
- Audit trail ชัดเจนว่าอะไร approved กับอะไร pending
3.6 Data Flow Summary
Flow ที่สมบูรณ์สำหรับการประมวลผลเอกสาร:
- Ingest — เอกสารเข้าสู่ pipeline
- Domain detect — LLM 1 เลือก domain ที่เกี่ยวข้อง
- Slice — ระบบดึง schema subset ที่เกี่ยวข้อง
- Extract — LLM 2 extract ด้วย sliced context
- Classify — แยก extraction ที่สำเร็จออกจาก gap
- Store — Triple ที่สำเร็จ → Neo4j; Gap → Proposal
- Validate — ตรวจสอบ proposal สำหรับ duplicate
- Queue — Proposal ที่ valid เข้าสู่ review queue
- Review — มนุษย์ approve/reject
- Apply — การเปลี่ยนแปลงที่ approved ถูก apply แบบ atomic
Section ถัดไปอธิบายรายละเอียด gap detection (Section IV) และ human review workflow (Section V)