II. Background
Section นี้สร้างพื้นฐานและวางตำแหน่งงานของเราภายในภูมิทัศน์การวิจัย
2.1 Knowledge Graph Fundamentals
Knowledge graph แสดงข้อมูลเป็นเครือข่ายของ entity ที่เชื่อมต่อด้วย typed relationship อย่างเป็นทางการ ประกอบด้วย:
- Entity — node ที่แทนวัตถุในโลกจริง (บริษัท, บุคคล, สถานที่)
- Relationship — directed edge ที่เชื่อมต่อ entity ด้วยความหมายทาง semantic
- Ontology — schema ที่กำหนด entity type, relationship type และ constraint ที่ถูกต้อง
Ontology ทำหน้าที่เป็นสัญญา: มันระบุว่าอะไรสามารถถูก represent ได้ Entity type (เช่น COMPANY, PERSON) กำหนดหมวดหมู่ ส่วน relationship type (เช่น WORKS_AT, OWNS) กำหนดการเชื่อมต่อที่ถูกต้องระหว่างกัน
บทบาทของ Ontology
Ontology ที่ออกแบบมาอย่างดีทำหน้าที่สี่ประการ:
- Schema enforcement — รับประกันความสอดคล้องของข้อมูลโดยตรวจสอบว่า entity และ relationship เป็นไปตาม type ที่กำหนด
- Query guidance — กำหนด traversal pattern ที่ถูกต้อง ทำให้สามารถ query แบบมีโครงสร้างได้
- Inference support — เปิดใช้งานการ reasoning เหนือโครงสร้างที่มี type (เช่น ถ้า X เป็นบริษัทลูกของ Y และ Y มีสำนักงานใหญ่ใน Z ดังนั้น X ดำเนินการใน Z)
- Integration anchor — ให้จุด mapping สำหรับรวมข้อมูลจากหลายแหล่ง
Ontology ที่ไม่สมบูรณ์สร้างจุดบอดอย่างเป็นระบบ — ข้อมูลที่มีอยู่ในโลกจริงแต่ไม่สามารถถูกบันทึกใน graph ได้
2.2 Ontology Evolution
Ontology ไม่ได้เป็นสิ่งคงที่ เมื่อ domain เปลี่ยนแปลงและแหล่งข้อมูลใหม่เกิดขึ้น schema ต้องวิวัฒนาการ Ontology evolution คือกระบวนการแก้ไข schema ในขณะที่รักษาความสอดคล้องกับข้อมูลที่มีอยู่
ประเภทของการเปลี่ยนแปลง
การแก้ไข schema แบ่งออกเป็นหลายหมวดหมู่:
- Additive — entity type ใหม่, relationship ใหม่, property ใหม่ สิ่งเหล่านี้ปลอดภัย: ข้อมูลที่มีอยู่ยังคงถูกต้อง
- Restrictive — constraint ที่เข้มงวดขึ้น, ตัวเลือกที่ถูกลบ สิ่งเหล่านี้อาจทำให้ข้อมูลที่มีอยู่ไม่ถูกต้อง
- Deprecation — ทำเครื่องหมาย element ว่าล้าสมัยในขณะที่รักษา backward compatibility
Framework ของเรามุ่งเน้นที่การเปลี่ยนแปลงแบบ additive เป็นหลัก — รูปแบบ evolution ที่พบบ่อยที่สุดเมื่อค้นพบ concept ใหม่ในข้อมูล
ความท้าทายของ Evolution
Schema evolution นำเสนอความยากลำบากหลายประการ:
- Consistency — การเปลี่ยนแปลงต้องไม่ทำให้ query ที่มีอยู่เสียหายหรือทำให้ข้อมูลที่เก็บไว้ไม่ถูกต้อง
- Redundancy — type ใหม่ไม่ควรซ้ำกับ concept ที่มีอยู่
- Propagation — ระบบที่พึ่งพา (API, application) ต้องได้รับการอัปเดต
- Versioning — การเปลี่ยนแปลงควรถูกติดตามเพื่อการทำซ้ำ
2.3 Automated Ontology Learning
การวิจัยได้สำรวจแนวทางต่างๆ สำหรับการสร้าง ontology อัตโนมัติ:
Statistical method ใช้ text pattern เพื่อค้นหา concept Hearst pattern เช่น "X such as Y" ระบุความสัมพันธ์ hyponymy สิ่งเหล่านี้ scale ได้ดีแต่ขาดความเข้าใจทาง semantic
Neural approach ใช้ embedding และ link prediction วิธีการเช่น TransE เรียนรู้ vector representation ที่ relationship ถูก model เป็น translation สิ่งเหล่านี้ปรับปรุงความแม่นยำแต่ทำงานภายใน schema คงที่ — พวกมันทำนาย edge ที่หายไป ไม่ใช่ type ที่หายไป
LLM-based extraction ใช้ large language model สำหรับ zero-shot information extraction เมื่อได้รับ schema และเอกสาร LLM สามารถระบุ entity และ relationship ได้ อย่างไรก็ตาม พวกมันมักจะ extract ภายใน schema ที่กำหนดแทนที่จะเสนอการแก้ไข schema
2.4 Knowledge Graph Completion
Knowledge graph completion (KGC) ทำนาย edge ที่หายไปใน graph เมื่อได้รับ fact ที่รู้ ระบบ KGC ทำนาย fact เพิ่มเติมที่น่าจะเป็นไปได้ — ตัวอย่างเช่น อนุมานว่าบุคคลทำงานที่บริษัทจาก LinkedIn profile ที่กล่าวถึงชื่อบริษัท
KGC ทำงานที่ instance level: เพิ่มข้อมูลภายใน schema ที่มีอยู่ งานของเราทำงานที่ schema level: แก้ไข ontology เอง สิ่งเหล่านี้เสริมกัน — KGC เติม fact ที่หายไป ส่วน ontology evolution ทำให้สามารถ represent fact ประเภทใหม่ได้
2.5 Human-in-the-Loop Systems
Human-in-the-loop (HITL) paradigm ผสานวิจารณญาณของมนุษย์เข้ากับระบบอัตโนมัติ ข้อมูลเชิงลึกที่สำคัญคือมนุษย์และ AI มีจุดแข็งที่เสริมกัน:
ระบบ HITL รวมสิ่งเหล่านี้ผ่าน collaboration model ต่างๆ:
- Active learning — AI เลือก sample ที่ให้ข้อมูลมากสำหรับให้มนุษย์ label
- Interactive ML — มนุษย์แก้ไข model prediction ระหว่าง training
- AI-assisted decision — AI เสนอ, มนุษย์ตัดสินใจ
Framework ของเราตาม model AI-assisted decision: AI สร้าง proposal ในขนาดใหญ่ มนุษย์ตัดสินใจ approval สิ่งนี้รักษาการควบคุมของมนุษย์เหนือการเปลี่ยนแปลง schema ในขณะที่ใช้ประโยชน์จากประสิทธิภาพของ AI
2.6 Related Work Positioning
Framework ของเราครองตำแหน่งที่เป็นเอกลักษณ์ในภูมิทัศน์:
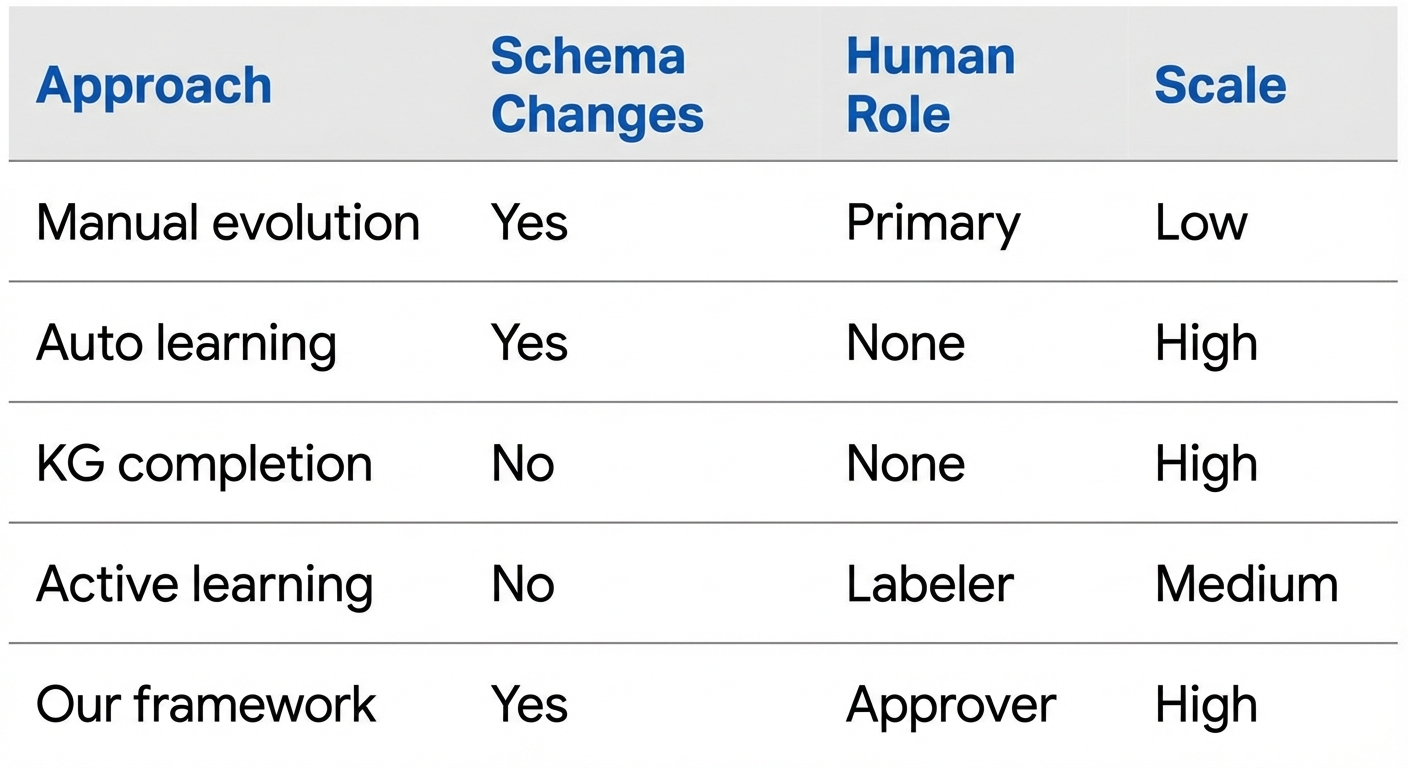
ความแตกต่างที่สำคัญ:
- Schema-level focus — เราวิวัฒนาการ ontology ไม่ใช่แค่ instance data
- Human oversight — การตัดสินใจต้องการ approval ที่ชัดเจน
- Proposal-based — AI สร้าง structured proposal ไม่ใช่การแก้ไขโดยตรง
- Context management — domain slicing เปิดใช้งานการใช้ LLM ในทางปฏิบัติ
2.7 Building Blocks
Framework ของเราผสานเทคนิคที่เป็นที่ยอมรับหลายอย่าง:
- LLM extraction — สำหรับการตรวจจับ gap และการสร้าง proposal
- Embedding similarity — สำหรับการตรวจจับ duplicate
- Domain modeling — สำหรับการจัดการ context
- HITL workflow — สำหรับการประกันคุณภาพ
Contribution ไม่ใช่เทคนิคเหล่านี้แต่ละอย่าง แต่เป็นการผสานเข้าด้วยกันเป็น framework ที่เชื่อมโยงสำหรับ AI-assisted ontology evolution