II. Background
This section establishes foundations and positions our work within the research landscape.
2.1 Knowledge Graph Fundamentals
A knowledge graph represents information as a network of entities connected by typed relationships. Formally, it consists of:
- Entities — nodes representing real-world objects (companies, people, places)
- Relationships — directed edges connecting entities with semantic meaning
- Ontology — the schema defining valid entity types, relationship types, and constraints
The ontology acts as a contract: it specifies what can be represented. Entity types (e.g., COMPANY, PERSON) define categories; relationship types (e.g., WORKS_AT, OWNS) define valid connections between them.
The Role of Ontology
A well-designed ontology serves four purposes:
- Schema enforcement — ensures data consistency by validating that entities and relationships conform to defined types
- Query guidance — defines valid traversal patterns, enabling structured queries
- Inference support — enables reasoning over typed structures (e.g., if X is a subsidiary of Y, and Y is headquartered in Z, then X operates in Z)
- Integration anchor — provides mapping points for combining data from multiple sources
An incomplete ontology creates systematic blind spots—information that exists in the real world but cannot be captured in the graph.
2.2 Ontology Evolution
Ontologies are not static. As domains change and new data sources emerge, schemas must evolve. Ontology evolution is the process of modifying a schema while maintaining consistency with existing data.
Types of Changes
Schema modifications fall into several categories:
- Additive — new entity types, new relationships, new properties. These are safe: existing data remains valid.
- Restrictive — tighter constraints, removed options. These may invalidate existing data.
- Deprecation — marking elements as obsolete while maintaining backward compatibility.
Our framework focuses primarily on additive changes—the most common evolution pattern when new concepts are discovered in data.
Evolution Challenges
Schema evolution presents several difficulties:
- Consistency — changes must not break existing queries or invalidate stored data
- Redundancy — new types should not duplicate existing concepts
- Propagation — dependent systems (APIs, applications) need updating
- Versioning — changes should be tracked for reproducibility
2.3 Automated Ontology Learning
Research has explored various approaches to automated ontology construction:
Statistical methods use text patterns to discover concepts. Hearst patterns like "X such as Y" identify hyponymy relations. These scale well but lack semantic understanding.
Neural approaches use embeddings and link prediction. Methods like TransE learn vector representations where relationships are modeled as translations. These improve accuracy but operate within fixed schemas—they predict missing edges, not missing types.
LLM-based extraction uses large language models for zero-shot information extraction. Given a schema and document, LLMs can identify entities and relationships. However, they typically extract within a given schema rather than proposing schema modifications.
2.4 Knowledge Graph Completion
Knowledge graph completion (KGC) predicts missing edges in a graph. Given known facts, KGC systems predict likely additional facts—for example, inferring that a person works at a company based on their LinkedIn profile mentioning the company name.
KGC operates at the instance level: adding data within an existing schema. Our work operates at the schema level: modifying the ontology itself. These are complementary—KGC fills in missing facts; ontology evolution enables representing new types of facts.
2.5 Human-in-the-Loop Systems
Human-in-the-loop (HITL) paradigms integrate human judgment into automated systems. The key insight is that humans and AI have complementary strengths:
HITL systems combine these through various collaboration models:
- Active learning — AI selects informative samples for human labeling
- Interactive ML — humans correct model predictions during training
- AI-assisted decision — AI proposes, human decides
Our framework follows the AI-assisted decision model: AI generates proposals at scale, humans make approval decisions. This preserves human control over schema changes while leveraging AI efficiency.
2.6 Related Work Positioning
Our framework occupies a unique position in the landscape:
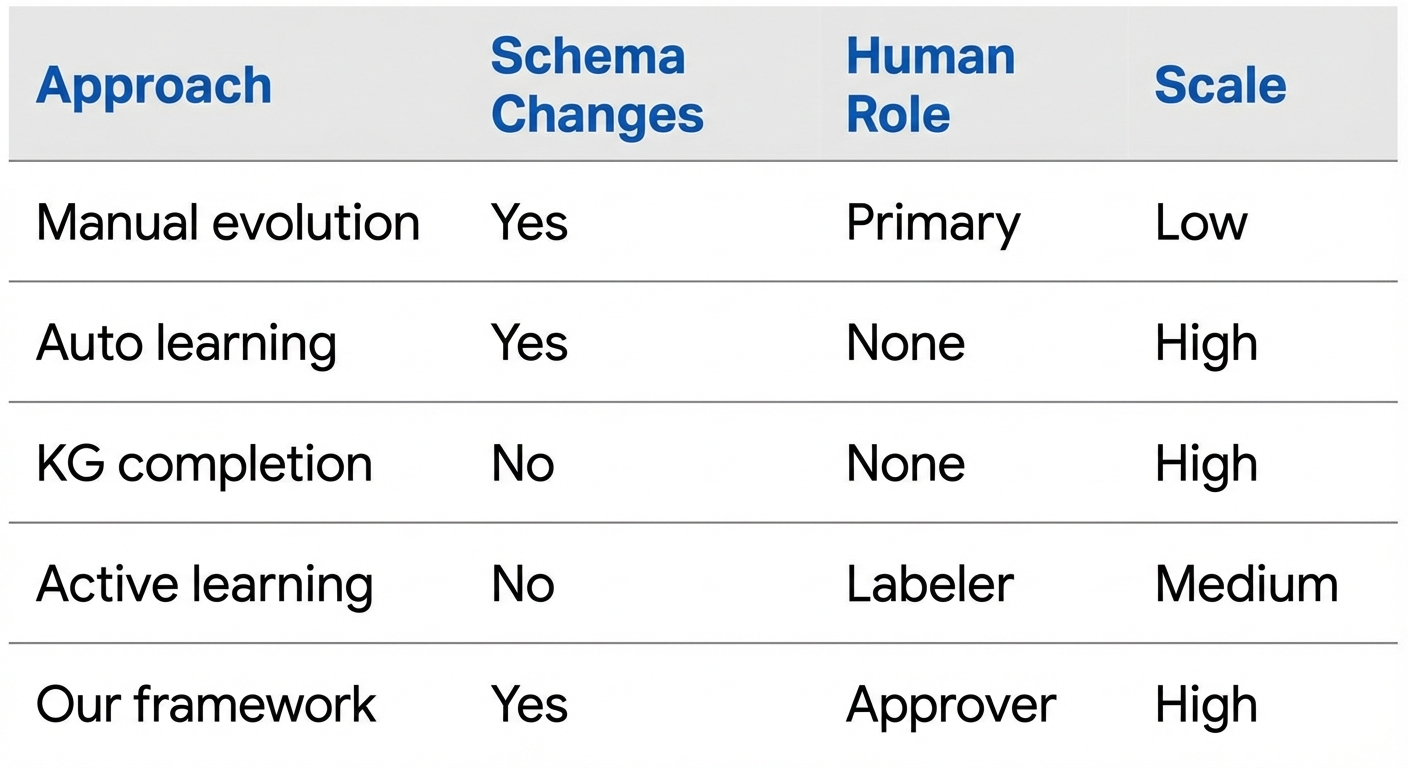
Key differentiators:
- Schema-level focus — we evolve ontologies, not just instance data
- Human oversight — decisions require explicit approval
- Proposal-based — AI generates structured proposals, not direct modifications
- Context management — domain slicing enables practical LLM usage
2.7 Building Blocks
Our framework integrates several established techniques:
- LLM extraction — for gap detection and proposal generation
- Embedding similarity — for duplicate detection
- Domain modeling — for context management
- HITL workflows — for quality assurance
The contribution is not these individual techniques but their integration into a cohesive framework for AI-assisted ontology evolution.