IV. Gap Detection & Proposals
This section details how the system identifies ontology gaps and generates structured proposals for human review.
4.1 What is a Gap?
An ontology gap occurs when document content cannot be represented using the current schema. Formally, given a document $D$ and current schema $S$, a gap exists when:
$$\exists\, c \in \text{concepts}(D) : \nexists\, t \in S \text{ where } \text{matches}(c, t)$$
In other words, the document contains a concept $c$ that has no matching type $t$ in the schema. The extraction process reveals gaps when it encounters such concepts.
Gaps fall into three categories:
- Entity gap — A concept has no matching entity type (e.g., "OPEC" when only COMPANY, COUNTRY, REGION exist)
- Relationship gap — A connection has no matching relationship type or violates type constraints
- Attribute gap — A property is not defined for an existing type
Gap Example
Document: "Saudi Arabia joined OPEC in 1960"
Current Schema:
Entities: COMPANY, COUNTRY, REGION
Rels: MEMBER_OF (Country -> Region)
Extraction Attempt:
"Saudi Arabia" -> COUNTRY (OK)
"OPEC" -> ??? (no matching type)
"joined" -> MEMBER_OF? (wrong target type)
Detected Gaps:
1. Entity gap: "OPEC" needs ORGANIZATION type
2. Relationship gap: Need Country->Org membership
4.2 Gap vs. Other Failures
Not every extraction failure indicates a true schema gap. The system must distinguish:
- True gap — Schema genuinely lacks the concept
- Data error — Document content is incorrect or malformed
- Wrong domain — The type exists but wasn't included in the slice
- Ambiguous — Cannot determine with confidence
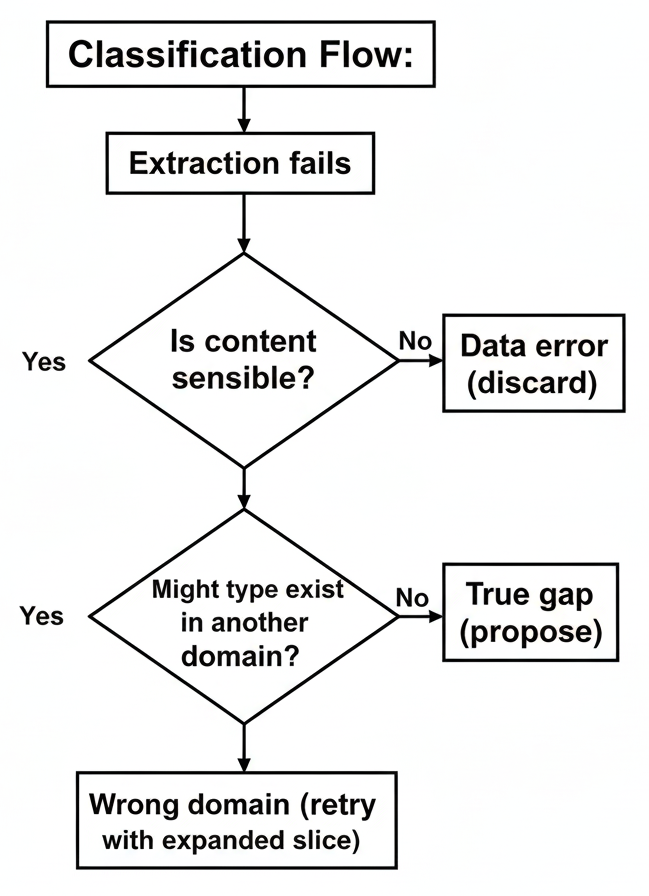
Wrong domain errors trigger a retry with additional domains before concluding a true gap exists.
4.3 Proposal Generation
When a true gap is confirmed, the system generates a structured proposal. The LLM is prompted to design appropriate schema modifications:
Generation Prompt:
You found a gap: "OPEC" has no entity type.
Current schema (CORE domain):
Entities: COMPANY, COUNTRY, REGION
Rels: HEADQUARTERS_IN, MEMBER_OF
Design a schema extension:
1. New entity type (SCREAMING_SNAKE_CASE)
2. Description (1-2 sentences)
3. Key properties
4. Any new relationships needed
5. Sample data to insert
Output JSON format...
Compound Proposals
Some gaps require multiple coordinated changes. For example, adding ORGANIZATION also requires adding an IS_MEMBER_OF relationship. These are bundled into a single proposal to be approved or rejected together.
4.4 Data Enrichment
Proposals include not just schema changes but also data enrichment—the instances to insert once approved. This provides immediate value from the schema extension.
Data Enrichment Example:
Schema Change:
+ ORGANIZATION entity
+ IS_MEMBER_OF relationship
Enrichment:
Create: OPEC (Organization)
Create: 13 membership relationships
- Saudi Arabia IS_MEMBER_OF OPEC
- Iran IS_MEMBER_OF OPEC
- Iraq IS_MEMBER_OF OPEC
- ...
The LLM can expand beyond the immediate document using its knowledge, though humans review the accuracy during approval.
4.5 Duplicate Detection
Before queueing proposals, the system checks for duplicates using embedding similarity. Each ontology element and proposal is embedded as a vector, and similarity is computed using cosine distance:
$$\text{sim}(p, e) = \frac{\mathbf{v}_p \cdot \mathbf{v}_e}{|\mathbf{v}_p| \cdot |\mathbf{v}_e|}$$
where $\mathbf{v}_p$ is the embedding of the new proposal and $\mathbf{v}_e$ is an existing element's embedding.
For new proposal "COOPERATES_WITH":
1. Embed: "COOPERATES_WITH: companies
working together on projects"
2. Search existing ontology embeddings
3. Search pending proposal embeddings
4. Flag if similarity > threshold
Similarity Results
Proposal: "COOPERATES_WITH"
Similar existing elements:
PARTNERS_WITH 0.94 (very similar!)
COLLABORATES_ON 0.89 (similar)
FORMS_JV_WITH 0.72
SOURCES_FROM 0.31
Action: Flag for review - likely duplicate
of PARTNERS_WITH
Conflict Handling
Based on similarity scores:
- > 0.95 — Likely duplicate; auto-reject or link to existing
- 0.85-0.95 — Similar; flag for human judgment
- < 0.85 — Distinct; proceed normally
This prevents ontology bloat from semantically equivalent types.
4.6 Pending Proposal Context
LLM Layer 2 sees not only the current ontology but also pending proposals. This prevents duplicate proposal generation:
Context for LLM Layer 2:
Current Schema:
COMPANY, COUNTRY, REGION...
Pending Proposals:
PROP-042: Add ORGANIZATION entity
(status: pending review)
---
If document mentions "OPEC":
-> Link to PROP-042 instead of
generating duplicate proposal
When a gap matches a pending proposal, the system links them rather than creating duplicates.
4.7 Confidence Scoring
Each proposal carries a confidence score reflecting the system's certainty that this is a valid schema extension. The score combines multiple factors:
$$C(p) = w_f \cdot f(p) + w_d \cdot (1 - d(p)) + w_s \cdot s(p)$$
where:
- $f(p)$ — Frequency: normalized count of similar gaps encountered
- $d(p)$ — Duplicate score: max similarity to existing elements (lower is better)
- $s(p)$ — Source quality: reliability score of originating document
- $w_f, w_d, w_s$ — weights summing to 1
High-confidence proposals surface first in the review queue.
4.8 Quality Considerations
Several mechanisms ensure proposal quality:
- Classification filtering — Only true gaps generate proposals
- Embedding validation — Duplicates are caught before review
- Confidence scoring — Uncertain proposals are flagged
- Human review — Final quality gate before application
The goal is maximizing useful proposals while minimizing noise in the review queue.