III. System Architecture
This section presents the overall system architecture, introducing the two-layer LLM approach and domain-based schema slicing.
3.1 Architecture Overview
The system comprises five main components working together to process documents, detect gaps, generate proposals, and apply approved changes:
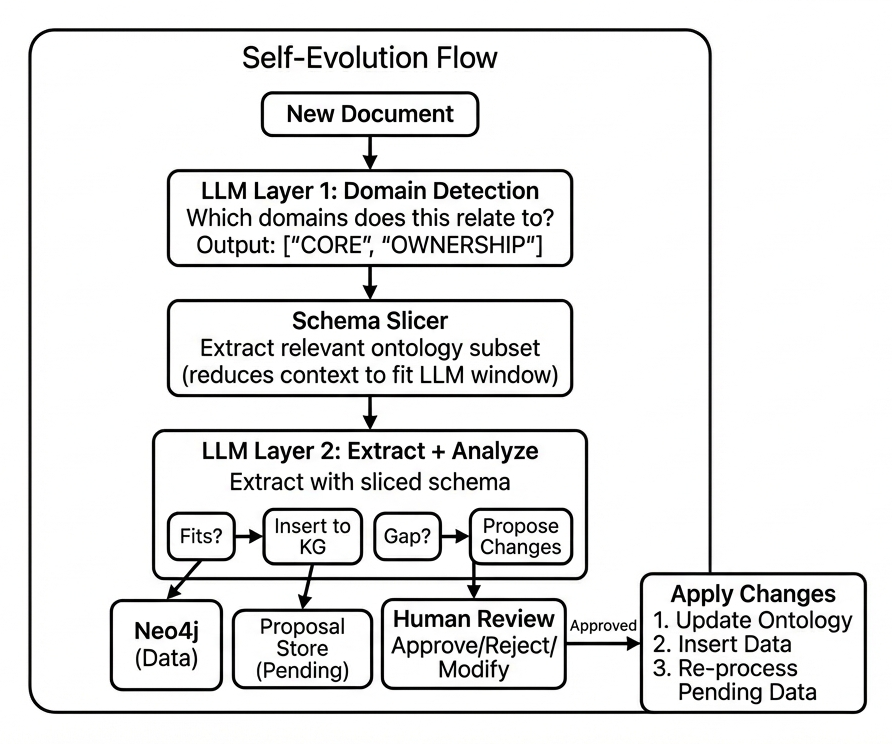
Component Responsibilities
- LLM Layer 1 — Domain detection: determines which ontology domains are relevant to a document
- Schema Slicer — Extracts only the relevant portion of the ontology
- LLM Layer 2 — Extraction and gap detection: attempts to extract data, identifies schema gaps
- Proposal Store — Holds pending proposals for human review
- Human Review — Approves, rejects, or modifies proposals
3.2 Two-Layer LLM Architecture
A naive approach would provide the entire ontology to a single LLM. This fails in practice because production ontologies often exceed context limits. Our solution splits the task across two specialized layers.
Why Two Layers?
Consider a production ontology with 50 entity types, 100 relationship types, and 200 pending proposals. Serialized, this might consume 35,000+ tokens—exceeding many model limits and incurring high costs.
The two-layer approach dramatically reduces context requirements:
Layer 1: Domain Selection
Input: Document + Domain list (~500 tokens)
Output: Selected domains (1-3)
Total: ~3,000 tokens
Layer 2: Extract + Analyze
Input: Document + Sliced schema (~2,000)
+ Relevant proposals (~3,000)
Output: Triples + Gaps + Proposals
Total: ~7,000 tokens
Total: ~10,000 tokens vs. ~35,000 for single-layer approach.
Layer 1: Domain Detection
The first layer receives a lightweight domain listing and determines relevance. The prompt structure:
Available Domains:
SUPPLY_CHAIN
Use when: suppliers, vendors, sourcing
Covers: supply chain, manufacturing
OWNERSHIP
Use when: shareholders, investors
Covers: ownership stakes, holdings
PARTNERSHIP
Use when: joint ventures, alliances
Covers: business partnerships
---
Document: [document text]
Select 1-3 domains. Output JSON:
{"domains": [...], "reasoning": "..."}
Layer 2: Extraction and Analysis
The second layer receives only the sliced schema plus pending proposals for those domains. It attempts extraction and reports gaps:
Schema (CORE + OWNERSHIP domains):
Entities:
COMPANY - Public or private company
COUNTRY - Nation
SHAREHOLDER - Entity holding shares
Relationships:
HEADQUARTERS_IN: Company -> Country
OWNS_SHARES: Shareholder -> Company
Pending Proposals:
PROP-042: Add ORGANIZATION entity
---
Document: [document text]
Extract triples using this schema.
Report any concepts that don't fit.
3.3 Domain-Based Schema Organization
The ontology is partitioned into semantic domains—groups of related entity and relationship types.
Domain Structure
Each domain contains:
- A name and description
- Usage hints (when to select this domain)
- Associated entity types
- Associated relationship types
- Flags (e.g.,
always_include)
Example domains for a financial knowledge graph:
CORE (always included)
Entities: COMPANY, COUNTRY, REGION
Rels: HEADQUARTERS_IN, MEMBER_OF
OWNERSHIP
Entities: SHAREHOLDER, FUND
Rels: OWNS_SHARES, MANAGES
SUPPLY_CHAIN
Entities: FACILITY, PRODUCT
Rels: SOURCES_FROM, MANUFACTURES_AT
PARTNERSHIP
Entities: JOINT_VENTURE
Rels: PARTNERS_WITH, FORMS_JV
Core Domain
The CORE domain contains foundational types (COMPANY, COUNTRY) that are relevant across most queries. It is automatically included in every slice, ensuring basic entity types are always available.
Slicing Algorithm
Given selected domains, the slicer retrieves:
- All entity types belonging to selected domains + CORE
- All relationship types belonging to selected domains + CORE
- Pending proposals tagged with these domains
Formally, given a set of selected domains $D_{sel}$, the schema slice is:
$$S_{slice} = S_{CORE} \cup \bigcup_{d \in D_{sel}} S_d$$
where $S_d$ denotes all schema elements (entities, relationships) belonging to domain $d$. The context reduction ratio is:
$$r = 1 - \frac{|S_{slice}|}{|S_{full}|}$$
In practice, $r$ typically falls between 0.6 and 0.8, meaning 60-80% context reduction.
3.4 Proposal Structure
When LLM Layer 2 detects a gap, it generates a structured proposal. A proposal contains:
{
"id": "PROP-042",
"title": "Add ORGANIZATION entity",
"status": "pending",
"domains": ["CORE"],
"ontology_changes": [
{
"type": "add_entity",
"name": "ORGANIZATION",
"description": "International org",
"properties": ["name", "org_type"]
},
{
"type": "add_relationship",
"name": "IS_MEMBER_OF",
"from": "COUNTRY",
"to": "ORGANIZATION"
}
],
"data_enrichment": {
"description": "OPEC + 13 members",
"sample_triples": [...]
},
"source": {
"document": "OPEC Report 2024",
"confidence": 0.92
}
}
Proposal Components
- Ontology changes — Schema modifications (add entity, add relationship, etc.)
- Data enrichment — Instance data to insert once approved
- Source — Provenance linking to the originating document
3.5 Storage Architecture
The system uses separate storage for different data types:
Neo4j (Graph Database)
- Entity instances
- Relationship instances
- Meta-schema (domain definitions)
- APPROVED data only
Postgres (Relational)
- Proposal records
- Status tracking
- Discussion history
- Pending extractions
pgvector (Vector Extension)
- Ontology embeddings
- Proposal embeddings
- For similarity search
Separation Rationale
Keeping proposals separate from production data ensures:
- Production graph contains only approved, validated data
- Pending proposals don't pollute queries
- Clear audit trail of what's approved vs. pending
3.6 Data Flow Summary
The complete flow for processing a document:
- Ingest — Document enters pipeline
- Domain detect — LLM 1 selects relevant domains
- Slice — System retrieves relevant schema subset
- Extract — LLM 2 extracts with sliced context
- Classify — Separate successful extractions from gaps
- Store — Successful triples → Neo4j; Gaps → Proposals
- Validate — Check proposals for duplicates
- Queue — Valid proposals enter review queue
- Review — Human approves/rejects
- Apply — Approved changes applied atomically
The following sections detail gap detection (Section IV) and the human review workflow (Section V).