IV. Gap Detection & Proposals
Section นี้อธิบายรายละเอียดวิธีที่ระบบระบุ ontology gap และสร้าง structured proposal สำหรับให้มนุษย์ตรวจสอบ
4.1 Gap คืออะไร?
Ontology gap เกิดขึ้นเมื่อเนื้อหาเอกสารไม่สามารถถูก represent ได้โดยใช้ schema ปัจจุบัน อย่างเป็นทางการ เมื่อกำหนดเอกสาร $D$ และ schema ปัจจุบัน $S$ gap มีอยู่เมื่อ:
$$\exists\, c \in \text{concepts}(D) : \nexists\, t \in S \text{ where } \text{matches}(c, t)$$
กล่าวอีกนัยหนึ่ง เอกสารมี concept $c$ ที่ไม่มี type $t$ ที่ตรงกันใน schema กระบวนการ extraction เผยให้เห็น gap เมื่อพบ concept เหล่านั้น
Gap แบ่งออกเป็นสามหมวดหมู่:
- Entity gap — Concept ไม่มี entity type ที่ตรงกัน (เช่น "OPEC" เมื่อมีเฉพาะ COMPANY, COUNTRY, REGION)
- Relationship gap — Connection ไม่มี relationship type ที่ตรงกันหรือละเมิด type constraint
- Attribute gap — Property ไม่ได้ถูกกำหนดสำหรับ type ที่มีอยู่
ตัวอย่าง Gap
Document: "Saudi Arabia joined OPEC in 1960"
Current Schema:
Entities: COMPANY, COUNTRY, REGION
Rels: MEMBER_OF (Country -> Region)
Extraction Attempt:
"Saudi Arabia" -> COUNTRY (OK)
"OPEC" -> ??? (no matching type)
"joined" -> MEMBER_OF? (wrong target type)
Detected Gaps:
1. Entity gap: "OPEC" needs ORGANIZATION type
2. Relationship gap: Need Country->Org membership
4.2 Gap vs. Failure อื่นๆ
ไม่ใช่ทุก extraction failure ที่บ่งชี้ถึง schema gap ที่แท้จริง ระบบต้องแยกแยะ:
- True gap — Schema ขาด concept จริงๆ
- Data error — เนื้อหาเอกสารไม่ถูกต้องหรือผิดรูปแบบ
- Wrong domain — Type มีอยู่แต่ไม่ได้ถูกรวมใน slice
- Ambiguous — ไม่สามารถกำหนดได้อย่างมั่นใจ
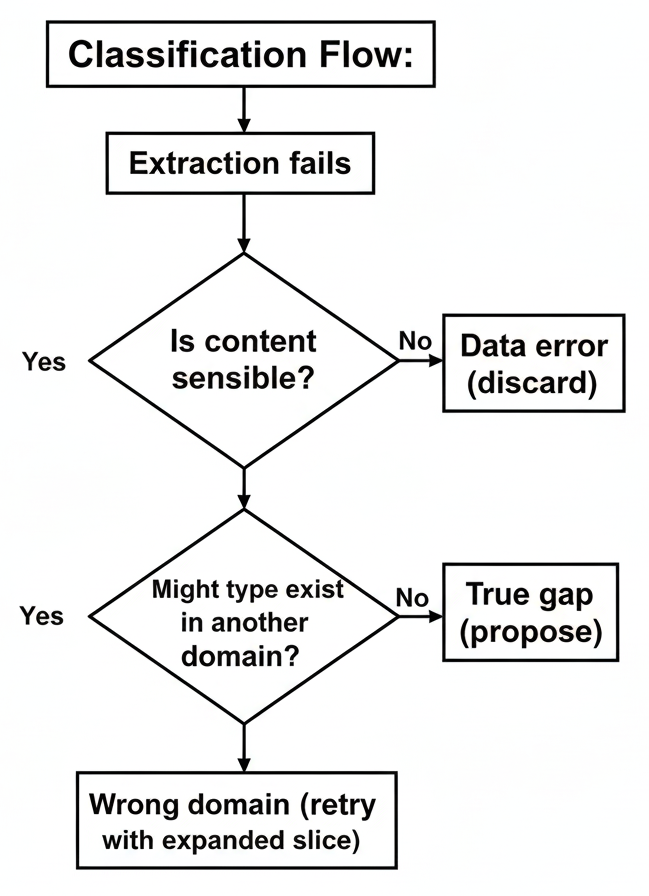
Wrong domain error ทริกเกอร์การ retry ด้วย domain เพิ่มเติมก่อนที่จะสรุปว่ามี true gap
4.3 Proposal Generation
เมื่อยืนยัน true gap แล้ว ระบบจะสร้าง structured proposal LLM ถูก prompt ให้ออกแบบการแก้ไข schema ที่เหมาะสม:
Generation Prompt:
You found a gap: "OPEC" has no entity type.
Current schema (CORE domain):
Entities: COMPANY, COUNTRY, REGION
Rels: HEADQUARTERS_IN, MEMBER_OF
Design a schema extension:
1. New entity type (SCREAMING_SNAKE_CASE)
2. Description (1-2 sentences)
3. Key properties
4. Any new relationships needed
5. Sample data to insert
Output JSON format...
Compound Proposal
บาง gap ต้องการการเปลี่ยนแปลงหลายอย่างที่ประสานกัน ตัวอย่างเช่น การเพิ่ม ORGANIZATION ยังต้องการเพิ่ม IS_MEMBER_OF relationship สิ่งเหล่านี้ถูกรวมเป็น proposal เดียวเพื่อ approve หรือ reject ด้วยกัน
4.4 Data Enrichment
Proposal ไม่ได้รวมเฉพาะการเปลี่ยนแปลง schema แต่ยังรวม data enrichment — instance ที่จะ insert เมื่อได้รับอนุมัติ สิ่งนี้ให้คุณค่าทันทีจาก schema extension
Data Enrichment Example:
Schema Change:
+ ORGANIZATION entity
+ IS_MEMBER_OF relationship
Enrichment:
Create: OPEC (Organization)
Create: 13 membership relationships
- Saudi Arabia IS_MEMBER_OF OPEC
- Iran IS_MEMBER_OF OPEC
- Iraq IS_MEMBER_OF OPEC
- ...
LLM สามารถขยายเกินกว่าเอกสารทันทีโดยใช้ความรู้ของมัน แม้ว่ามนุษย์จะตรวจสอบความถูกต้องระหว่าง approval
4.5 Duplicate Detection
ก่อน queue proposal ระบบตรวจสอบ duplicate โดยใช้ embedding similarity แต่ละ ontology element และ proposal ถูก embed เป็น vector และคำนวณ similarity โดยใช้ cosine distance:
$$\text{sim}(p, e) = \frac{\mathbf{v}_p \cdot \mathbf{v}_e}{|\mathbf{v}_p| \cdot |\mathbf{v}_e|}$$
โดยที่ $\mathbf{v}_p$ คือ embedding ของ proposal ใหม่ และ $\mathbf{v}_e$ คือ embedding ของ element ที่มีอยู่
For new proposal "COOPERATES_WITH":
1. Embed: "COOPERATES_WITH: companies
working together on projects"
2. Search existing ontology embeddings
3. Search pending proposal embeddings
4. Flag if similarity > threshold
ผลลัพธ์ Similarity
Proposal: "COOPERATES_WITH"
Similar existing elements:
PARTNERS_WITH 0.94 (very similar!)
COLLABORATES_ON 0.89 (similar)
FORMS_JV_WITH 0.72
SOURCES_FROM 0.31
Action: Flag for review - likely duplicate
of PARTNERS_WITH
การจัดการ Conflict
ตาม similarity score:
- > 0.95 — น่าจะเป็น duplicate; auto-reject หรือ link ไปยังที่มีอยู่
- 0.85-0.95 — คล้ายกัน; flag สำหรับ human judgment
- < 0.85 — แตกต่าง; ดำเนินการตามปกติ
สิ่งนี้ป้องกัน ontology bloat จาก type ที่เทียบเท่ากันทาง semantic
4.6 Pending Proposal Context
LLM Layer 2 เห็นไม่เฉพาะ ontology ปัจจุบันแต่รวมถึง pending proposal ด้วย สิ่งนี้ป้องกันการสร้าง proposal ซ้ำ:
Context for LLM Layer 2:
Current Schema:
COMPANY, COUNTRY, REGION...
Pending Proposals:
PROP-042: Add ORGANIZATION entity
(status: pending review)
---
If document mentions "OPEC":
-> Link to PROP-042 instead of
generating duplicate proposal
เมื่อ gap ตรงกับ pending proposal ระบบจะ link แทนที่จะสร้าง duplicate
4.7 Confidence Scoring
แต่ละ proposal มี confidence score ที่สะท้อนความมั่นใจของระบบว่านี่คือ schema extension ที่ถูกต้อง Score รวมหลายปัจจัย:
$$C(p) = w_f \cdot f(p) + w_d \cdot (1 - d(p)) + w_s \cdot s(p)$$
โดยที่:
- $f(p)$ — Frequency: จำนวน normalized ของ gap ที่คล้ายกันที่พบ
- $d(p)$ — Duplicate score: max similarity กับ element ที่มีอยู่ (ยิ่งต่ำยิ่งดี)
- $s(p)$ — Source quality: reliability score ของเอกสารต้นทาง
- $w_f, w_d, w_s$ — weight ที่รวมกันเป็น 1
Proposal ที่มี confidence สูงจะปรากฏก่อนใน review queue
4.8 Quality Considerations
หลาย mechanism รับประกันคุณภาพ proposal:
- Classification filtering — เฉพาะ true gap เท่านั้นที่สร้าง proposal
- Embedding validation — Duplicate ถูกจับก่อน review
- Confidence scoring — Proposal ที่ไม่แน่นอนถูก flag
- Human review — Quality gate สุดท้ายก่อน application
เป้าหมายคือการ maximize proposal ที่มีประโยชน์ในขณะที่ minimize noise ใน review queue