I. Introduction
1.1 Motivation
Knowledge graphs have become essential for representing structured information in finance, healthcare, and e-commerce. A knowledge graph consists of entities (nodes representing real-world objects), relationships (edges connecting entities), and an ontology (schema defining valid types).
The ontology determines what can be represented. If a concept exists in the real world but not in the ontology, it cannot be captured in the knowledge graph. This creates a fundamental limitation: as domains evolve and new data arrives, ontologies become outdated.
1.2 A Concrete Example
Consider a financial knowledge graph with this simple ontology:
- Entity types: COMPANY, COUNTRY, REGION
- Relationship: MEMBER_OF (Country → Region)
When processing a document stating:
"Saudi Arabia is a founding member of OPEC since 1960"
The system encounters a problem:
- "OPEC" is not a COMPANY, COUNTRY, or REGION—it's an international organization
- The membership relationship between a Country and an Organization doesn't exist
Without schema evolution, this information is lost. The ontology evolution problem is: how can we systematically identify such gaps and update the schema while maintaining data quality?
1.3 Existing Approaches
Current approaches have significant limitations:
Manual Evolution: Domain experts review data and update ontologies by hand. This ensures quality but doesn't scale—experts cannot review every document, and schema updates become bottlenecks.
Fully Automated Evolution: Machine learning systems modify ontologies without human oversight. This scales well but risks creating redundant types, semantic inconsistencies, and errors that propagate undetected.
1.4 Our Approach
We propose a middle path: AI-assisted evolution with human-in-the-loop approval. The key insight is to separate proposal generation (which AI can do at scale) from decision-making (which requires human judgment).
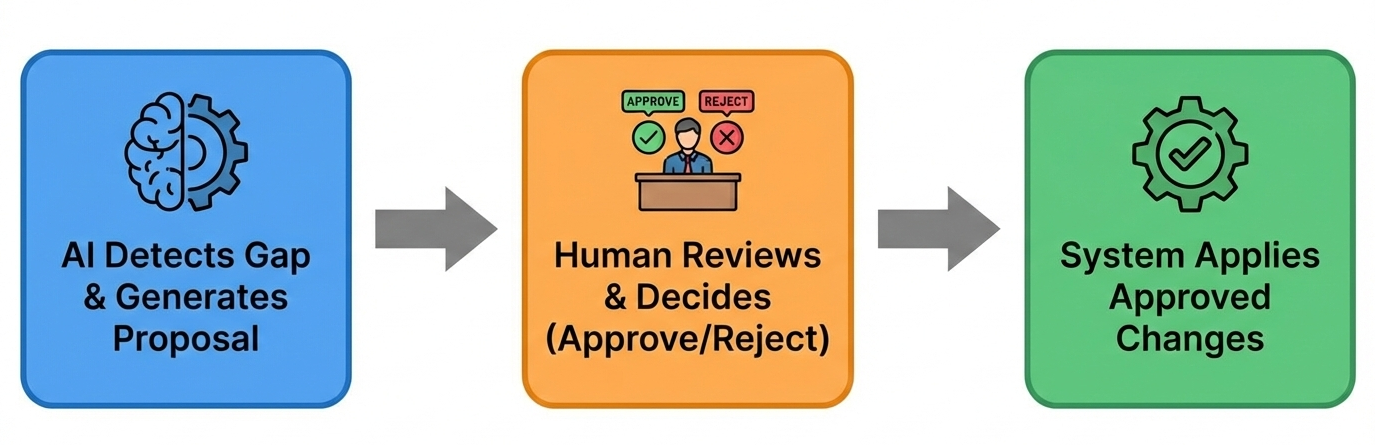
This combines AI's ability to process documents at scale with human expertise for quality control. The hypothesis is simple:
1.5 Technical Challenges
Implementing this approach requires solving several problems:
Challenge 1: Context Limits. Large language models have bounded context windows. A production ontology with hundreds of types exceeds these limits. We address this through domain-based schema slicing—partitioning the ontology into semantic domains and providing only relevant portions to the LLM.
Challenge 2: Gap vs. Error. When extraction fails, it might indicate a true schema gap, a data error, or simply wrong domain selection. The system must classify failures accurately to avoid generating spurious proposals.
Challenge 3: Proposal Conflicts. Different documents may trigger similar proposals. Without validation, the system might propose "PARTNERS_WITH" and "COOPERATES_WITH" for the same concept. We use embedding-based similarity detection to identify duplicates.
Challenge 4: Review Backlog. Humans aren't always available. Proposals accumulate between review sessions, requiring batch processing while maintaining consistency.
1.6 Contributions
This paper makes four contributions:
- Framework Design — A complete architecture for AI-assisted ontology evolution with human oversight
- Domain-Based Slicing — A method for managing LLM context through ontology partitioning
- Proposal Workflow — A structured process from gap detection through human review to batch application
- Embedding Validation — Similarity-based duplicate detection for proposal quality
1.7 Scope
This work presents a conceptual framework with implementation guidance. We note that:
- This is a framework design, not a production system
- Experimental validation is planned for future work
- Human review remains essential—this is not fully autonomous
The goal is to establish foundations for AI-assisted knowledge graph maintenance.
1.8 Paper Organization
Section II provides background on knowledge graphs and related work. Section III presents system architecture. Sections IV and V detail gap detection and human workflow. Section VI discusses implementation. Sections VII and VIII cover limitations and conclusions.